

Scaling NVIDIA's multi-speaker multilingual TTS systems with voice cloning to Indic Languages
We, at NVIDIA, recently won the MMITS-VC (Multi-speaker, Multi-lingual Indic Text-To-Speech/TTS with Voice Cloning) 2024 Challenge.

We, at NVIDIA, recently won the MMITS-VC (Multi-speaker, Multi-lingual Indic Text-To-Speech/TTS with Voice Cloning) 2024 Challenge. We used RAD-MMM and P-Flow (developed by NVIDIA’s Applied Deep Learning Research team) that delivered strong performance on the few-shot text-to-speech (TTS) and zero-shot TTS scenarios respectively. RAD-MMM performed competitively in Tracks 1 and 2, while P-Flow ranked first in Track 3, demonstrating its exceptional zero-shot TTS capabilities. Here is a short 2-page technical system description of our system for ICASSP 2024. Furthermore, in this blog, I walk you through how we approached this challenge:
MMITS-VC Challenge.
Summary of NVIDIA’s approach
Data Pre-Processing
Track 1 & 2: Few-shot TTS with RAD-MMM
Track 3: Zero-shot TTS with P-Flow
HiFi-GAN Vocoders
Results and Conclusion
The NVIDIA team included NVIDIA researchers: Akshit Arora, Rohan Badlani, Sungwon Kim and Rafael Valle.
MMITS-VC Challenge

Background
The Signal Processing, Interpretation and REpresentation (SPIRE) Laboratory at Indian Institute of Science (IISc) in Bangalore (India) organized the MMITS-VC challenge, one of the grand challenges, organized as part of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2024.
As part of the challenge, TTS data of 80 hours was released in each of Bengali, Chhattisgarhi, English and Kannada languages. This was in addition to Telugu, Hindi and Marathi data released in the LIMMITS 23. Each language had a male and a female speaker, resulting in a TTS corpora of 7 languages and 14 speakers. TTS corpora in these languages are built as a part of the SYSPIN (SYnthesizing SPeech in INdian languages) project at SPIRE lab, Indian Institute of Science (IISc) Bangalore, India.
In this challenge, we present the opportunity for the participants to perform TTS Voice cloning with a multilingual base model of 14 speakers. We further extend this scenario, allowing training with more multi-speaker corpora such as VCTK, LibriTTS. Finally, we also present a scenario for zero-shot voice cloning (VC). Towards these, we share 560 hours of studio-quality TTS data in 7 Indian languages. This includes low-resource language of Chattisgarhi. The evaluation will be performed on mono as well as cross-lingual synthesis, across data from all 7 languages, with naturalness and speaker similarity subjective tests.
— Source: MMITS-VC 24 Website
Challenge Tracks
There were 3 challenge tracks:
Track 1 - Few shot TTS+VC with challenge dataset
Using a pre-trained multi-lingual, multi-speaker TTS built on the challenge dataset, perform a few shot voice cloning by fine-tuning new speakers.
Track 2 - Few shot TTS + VC with challenge + external datasets
Using a pre-trained multi-lingual, multi-speaker TTS built on datasets of this challenge and any other publicly available corpora such as VCTK, LibtiTTS etc., perform few-shot voice cloning by fine-tuning on new speakers.
Track 3 - Zero shot TTS + VC with challenge + external datasets
Using a pre-trained multi-lingual, multi-speaker TTS built on datasets of this challenge and any other publicly available corpora such as VCTK, LibtiTTS etc., evaluate on utterances of unseen speakers.

Datasets Used
Challenge dataset
The challenge organizers shared a TTS corpus of 14 speakers, of 7 Indian languages with 40 hours of data from each speaker, resulting in the challenge corpora of 560 hours. Here are the 7 languages: Bengali, Chhattisgarhi, English, Kannada, Marathi, Telugu and Hindi. Link here.
Few-shot dataset
The target speakers for all tracks are as follows:
3 unseen Hindi speakers (F - IndicTTS - Indian, M - IndicTTS - Indian, F - SPIRE - Indian )
3 unseen Kannada speakers (F - IndicTTS - Indian, M - IndicTTS - Indian, M - SPIRE - Indian)
3 speakers from VCTK - 248 (F - Indian), 294 (F - English), 326 (M - Australian)
For Track 1 and 2, data corresponding to 5 mins of audio is provided for each of the target speakers listed above for few shot training. This dataset is not used for Track 3 training, as track 3 model is required to have zero shot TTS capabilities. I refer to this dataset as the few shot dataset for the remainder of this blog, and it is available at this link.
External Datasets
External pretrained TTS models or vocoders are allowed only for tracks 2 and 3. For track 3, pretrained models should not be trained on target speakers. As per these guidelines, we use LibriTTS (for RAD-MMM and P-Flow in tracks 2 and 3 respectively) and VCTK (for vocoders in Tracks 2 and 3).
Challenge Evaluation
The submissions were evaluated on naturalness and speaker similarity scores, for mono lingual and cross lingual synthesis.
Each submission involved ratings from overall 144 utterances, with equal split across mono lingual and cross lingual synthesis. The breakdown is shown below.
Each submission will be evaluated by multiple evaluators, native to the target language.
If there are more than 10 submissions, the top ten teams will be first selected based on objective scores (Character Error Rate). The subjective evaluation will be done for the top 10 teams (Naturalness and Speaker Similarity)
The test set utterances and all the relevant metadata are available were made available to download from this link - https://drive.google.com/file/d/1vhjWcDk3UYrh2_bOb202f6LKj8jlNvLT/view?usp=sharing

Summary of our Approach
There has been incredible progress in the quality of Text-To-Speech (TTS) models, specially in zero-shot TTS with large-scale neural codec autoregressive language models. Unfortunately, these models inherit several drawbacks from earlier autoregressive models: they require collecting thousands of hours of data, rely on pre-trained neural codec representations, lack robustness, and have very slow sampling speed. These issues are not present in the models we propose here i.e. RAD-MMM1 and P-Flow2.
NVIDIA's approach for Tracks 1 and 2 involves utilizing RAD-MMM for few-shot TTS. RAD-MMM disentangles attributes like speaker, accent, and language, enabling the model to synthesize speech for a desired speaker, language, and accent without relying on bilingual data.
For Track 3, NVIDIA employed P-Flow, a fast and data-efficient zero-shot TTS model. P-Flow leverages speech prompts for speaker adaptation, allowing it to synthesize speech for unseen speakers with just a short audio sample.
Data Pre-processing
We reprocess the provided speech data (challenge and few-shot datasets) by:
Removing any empty audio files,
Removing clips with duplicate transcripts,
Trimming leading and trailing silences
Normalizing audio volume.
The following table captures the final data statistics, after pre-processing is complete:

Track 1 & 2: Few-shot TTS with RAD-MMM
Why RAD-MMM?
Our goal, in Tracks 1 and 2, is to create a multi-lingual TTS system that can synthesize speech in any target language (with a target language's native accent) for any speaker seen by the model. We use RAD-MMM to disentangle attributes such as speaker, accent and language, such that the model can synthesize speech for the desired speaker, and the desired language and accent, without relying on any bi-lingual data.
How we trained RAD-MMM?
Our goal is to develop a model for multilingual synthesis in the languages of interest with the ability of cross-lingual synthesis for a (seen) speaker of interest. Our dataset comprises each speaker speaking only one language and hence there are correlations between text, language, accent and speaker within the dataset. Recent work on RAD-MMM tackles this problem by proposing several disentanglement approaches. Following RAD-MMM, we use deterministic attribute predictors to separately predict fine-grained features like fundamental frequency (F0) and energy given text, accent and speaker.
In our setup, we leverage the text pre-processing, shared alphabet set and the accent-conditioned alignment learning mechanism proposed in RAD-MMM. We consider language to be implicit in the phoneme sequence, whereas the information captured by the accent should explain the fine-grained differences between how phonemes are pronounced in different languages.

3.2.1. Track 1
We train RAD-MMM on the challenge dataset described in Section “Dataset and Preprocessing”. Since the few-shot dataset is very small (5 mins per speaker), to avoid overfitting on small-data speakers, we fine-tune the trained RAD-MMM model with both challenge and few-show data for 5000 iterations and batch size 8.
3.2.1. Track 2
We train RAD-MMM on the challenge dataset, LibriTTS and VCTK (excluding target evaluation speakers from the few-shot dataset, following challenge guidelines). Even though the additional datasets (LibriTTS and VCTK) are English only, they contain many speakers, thus helping the model generalize better. Similarly to Track 1, we avoid overfitting by fine-tuning this RAD-MMM model on challenge and few-shot data for 5000 iterations and batch size 8.
Track 3: Zero-shot TTS with P-Flow
Why P-Flow?
In Track 3, our goal is to create a multilingual TTS system that synthesizes speech in any seen target language given a speech prompt. We use P-Flow, a fast and data-efficient zero-shot TTS model that uses speech prompts for speaker adaptation.
How we trained P-Flow?
In Track 3, our goal is to perform zero-shot TTS for multiple languages using reference data for speakers unseen during training. The challenge dataset contains speech samples from two speakers for each language, with at most 14 speakers. To achieve zero-shot TTS for new speakers, it is necessary to learn to adapt to a variety of speakers. Therefore, we additionally utilize the English multi-speaker dataset, LibriTTS, to alleviate the shortage of speakers in the Indic languages of the challenge dataset.
Recently, P-Flow has demonstrated strong ability for zero-shot TTS in English by introducing speech prompting for speaker adaptation. P-Flow performs zero-shot TTS using only 3 seconds of reference data for the target speaker. We expand this capability for cross-lingual zero-shot, extending the model's zero-shot TTS ability from its original language, English, to include seven additional Indic languages. To achieve this, we modify P-Flow's decoder architecture, extend the training data to include the challenge dataset, and use RAD-MMM's text pre-processing to expand to other languages.
We train this modified version of P-Flow on both LibriTTS and the challenge datasets, filtering out audio samples shorter than 3 seconds. In total, we utilize 964 hours of speech data from 2287 speakers, comprising 14 speakers from the challenge dataset and an additional 2273 speakers from LibriTTS. We train P-Flow on 8 A100 GPUs, each with a batch size of 8 samples, achieving the same effective batch size of 64 as in the original P-Flow paper. We follow the same training details as the P-Flow paper.
During inference, we use Euler's method for sampling with the default setup of P-Flow, with a classifier-free guidance scale of 1 and 10 sampling steps. For evaluation, we only use 3 seconds of speech from the given target speaker for zero-shot TTS. Specifically, we randomly select one sample corresponding to 3-4 seconds from each target speaker's reference sample and only crop the first 3 seconds for use. Note that we do not use the transcript for the reference sample, so the model does not receive information about the language being used.

HiFi-GAN Vocoders
For Track 1, we use the challenge dataset to train a mel-conditioned HiFi-GAN3 vocoder model for both mono and cross lingual scenarios. For Track 3, we use the challenge and VCTK datasets (excluding target evaluation speakers from few-shot dataset, following challenge guidelines) to train a HiFi-GAN vocoder model from scratch. For Track 2, we further finetune the vocoder trained for Track 3 on the few-shot training dataset provided by challenge organizers. We use NVIDIA’s NeMo to train the HiFi-GAN model implemented here on A10G GPUs.
Challenge Results & Conclusion
Results
The submissions were evaluated by listening tests assessing quality, similarity to target speaker, etc. RAD-MMM delivered strong performance on the few-shot tracks, while P-Flow with its zero-shot capabilities won the third track. On average, NVIDIA's systems achieved a mean opinion score (MOS) of 4.4 out of 5 for quality, and 3.62 out of 5 for similarity to the target speaker.
Track 3 Naturalness:

Track 3 Speaker Similarity:
Track 2 Naturalness:

Track 2 Speaker Similarity:

Track 1 Naturalness:

Track 1 Speaker Similarity:
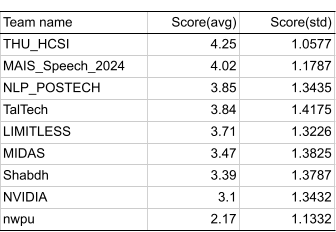
Conclusion
This paper presents the TTS systems developed by NVIDIA for the MMITS-VC Challenge 2024. We use RAD-MMM for few-shot TTS scenarios (Tracks 1 and 2) because of its ability to disentangle speaker, accent and text for high-quality multilingual speech synthesis without relying on bi-lingual data. We use P-Flow for zero-shot TTS scenario (Track 3) as alongside HiFi-GAN based vocoder models due to its ability to perform zero-shot TTS with a short 3 seconds audio sample. The challenge evaluation shows that RAD-MMM performs competitively on Tracks 1 and 2, while P-Flow ranks first on Track 3.
Overall, NVIDIA's achievement signals that speech synthesis is becoming increasingly effective and versatile, paving the way for next-generation vocal interfaces.
Annexure
Background of SYSPIN
Providing people with information in their own native language is a key driver of economic empowerment and political participation. However, the diversity and lack of technological support for spoken languages in India makes universal access to information and services an ongoing challenge. The advancement of artificial intelligence-driven speech technology is yet to meet the requirements in many of the low-resourced Indian languages that suffer from the unavailability of linguistic expertise and electronic resources. This increases the necessity for the development of corpora and systems for the development of various speech technology solutions to provide different voice-based user-friendly applications.
So here is the SYSPIN to develop and open source a large corpus and models for text-to-speech (TTS) systems in multiple Indian languages. It reduces the main barriers to voice-based technologies and creates a potential market for technical innovators and social entrepreneurs. Nine Indian languages considered for this project are Hindi, Bengali, Marathi, Telugu, Bhojpuri, Kannada, Magadhi, Chhattisgarhi, and Maithili. The development of TTS corpora and AI models potentially benefits 602.1 million speakers of these languages. Overall, the collection of open voice data strengthens the local AI ecosystem for the development of voice technologies.
The output of this project will allow local innovation in emerging markets to develop products and services serving illiterate Indians and rural poor populations in their own medium of engagement with technology. The TTS corpus will be a unique resource for developing assistive technologies for people with speech and visual disabilities. The proposed 720 hours of open-source TTS data will open up opportunities for academic and industrial research.
LibriTTS Dataset
LibriTTS is a multi-speaker English corpus of approximately 585 hours of read English speech at 24kHz sampling rate, prepared by Heiga Zen with the assistance of Google Speech and Google Brain team members. The LibriTTS corpus is designed for TTS research. It is derived from the original materials (mp3 audio files from LibriVox and text files from Project Gutenberg) of the LibriSpeech corpus.
VCTK Dataset
This CSTR VCTK Corpus (Centre for Speech Technology Voice Cloning Toolkit) includes speech data uttered by 109 native speakers of English with various accents. Each speaker reads out about 400 sentences, most of which were selected from a newspaper plus the Rainbow Passage and an elicitation paragraph intended to identify the speaker's accent.
References
Project Page: https://aroraakshit.github.io/mmitsvc-2024/
SYSPIN initiative: https://syspin.iisc.ac.in/
SPIRE Lab: https://ee.iisc.ac.in/~prasantg/index.html
RAD-MMM homepage: https://research.nvidia.com/labs/adlr/projects/radmmm/
P-Flow homepage: https://pflow-demo.github.io/projects/pflow/
Rohan Badlani, Rafael Valle, Kevin J. Shih, João Felipe Santos, Siddharth Gururani, and Bryan Catanzaro, “Radmmm: Multilingual multiaccented multispeaker text to speech,” arXiv, 2023. Samples for RADMMM available here.
Sungwon Kim, Kevin J. Shih, Rohan Badlani, Joao Felipe Santos, Evelina Bakhturina, Mikyas T. Desta, Rafael Valle, Sungroh Yoon, and Bryan Catanzaro, “P-flow: A fast and data-efficient zero-shot TTS through speech prompting,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023. Samples available here.
Kong, J., Kim, J., and Bae, J. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, virtual, 2020. Code available here.