

VANI (वाणी)
Very-lightweight Accent-controllable TTS for Native and Non-native speakers with Identity Preservation

In October 2022, we formed a team within NVIDIA to tackle the first of its kind LIMMITS (LIghtweight, Multi-speaker, Multi-lingual Indic TTS) 2024 challenge. We primarily used RAD-MMM (developed by NVIDIA’s Applied Deep Learning Research team) and developed its lightweight variant (named “VANI” or “वाणी” - meaning speech in Hindi) that delivered strong performance on limited data and lightweight model scenarios respectively. VANI performed competitively in Track 2 & 3, while RAD-MMM ranked first in Track 1 in terms of speaker similarity scores. Here is a short 2-page technical system description of our system for ICASSP 2024. Furthermore, in this blog, I walk you through how we approached this challenge:
LIMMITS Challenge
Summary of NVIDIA’s approach
Data Pre-Processing
Track 1: Large-parameter setup, Small-data
Track 2: Small-parameter, Large-data setup
Track 3: Small-parameter, Small-data setup
Vocoder setup
Results and Analysis
The NVIDIA team (team name VAANI) included NVIDIA researchers: Rohan Badlani, Akshit Arora, Subhankar Ghosh, Boris Ginsburg and Rafael Valle.
LIMMITS Challenge

Background
The Signal Processing, Interpretation and REpresentation (SPIRE) Laboratory at Indian Institute of Science (IISc), Bangalore (India) organized the LIMMITS challenge, one of the grand challenges, organized as part of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2023.
As part of this challenge, TTS data of 80 hours was released in each of Hindi, Marathi and Telugu. Each language had a male and a female speaker, resulting in a TTS corpora of 3 languages and 6 speakers. TTS corpora in these languages are built as a part of the SYSPIN (SYnthesizing SPeech in INdian languages) project at SPIRE lab, IISc Bangalore.
The challenge is being organized as part of ICASSP 2023 which aims at the development of a Lightweight, Multi-speaker, Multi-lingual Indic Text-to-Speech (TTS) model using datasets in Marathi, Hindi, and Telugu. These studies are important for data selection in TTS, for various landscapes such as India, Europe, etc which have a large number of languages and their regional variations. TTS corpora in these languages are being built as a part of the SYSPIN project at SPIRE lab, Indian Institute of Science (IISc) Bangalore, India, in which large corpora comprising 40 hours of single speaker’s speech in each of nine Indian languages are being collected. This proposal is part of the initiatives taken to open source these corpora and continue to propose challenges in the next two years’ ICASSP as well.
The challenge aims towards helping and encouraging the advancement of TTS in Indian Languages. The basic challenge is to take the released speech data, build TTS voices, and share the voice in web API form for evaluation. The output from each synthesizer will be evaluated through extensive listening tests. The primary objective of this challenge is understanding and comparing the various approaches to build TTS and simultaneously identifying efficient speech groups across the world.
- Source: LIMMITS’23 website
Challenge Tracks
There were 3 challenge tracks:
Track 1 - Data Selection
Recent literature has shown that a limited amount of data may be sufficient to build high-quality speech synthesis models for multiple speakers and languages setup.
In this sub-track, we share 40 hours of data from each of the six speakers, from which participants can use a maximum of 5 hours of data, from each speaker, to train one multispeaker, multilingual model.
The goal is to identify subsets of data from the larger corpus, which can be used for multispeaker, multilingual TTS training. The presence of parallel sentences across speakers in a language can also be exploited in this formulation.
Track 2 - Lightweight TTS
The size of the TTS model is an important detail to be considered while deploying such models for practical use. It is not economical to host large-scale models built for research for many applications. Also, it would be ideal to incorporate a multitude of speakers and languages in a single model to further lower the cost of hosting models.
Towards this, we propose this track to build lightweight multispeaker, multi-lingual TTS models, which can employ techniques such as model distillation, compression, lighter model architectures, etc. In this problem statement, we limit the TTS model (text to Mel spectrogram) to have 5M usable parameters while a fixed vocoder is to be used as provided by the organizers. This limit is set based on the advances made in recent works in TTS.
Track 3 - Lightweight model development from best data
This track is a combination of Track 1 and Track 2.The participants are required to build one multi-speaker, multi-lingual, lightweight speech synthesis model by utilizing at max 5 hours of data from each speaker, and overall model (text to Mel spectrogram) parameters to be less than 5M. The participants must use the vocoder provided by the organizers.
Vocoder rules:
Track 1: Any vocoder can be used as long as it is trained only on challenge data.
Track 2 & 3:
For fair evaluation across teams, participants must use the vocoder provided by the organizers to synthesize speech. Speaker-specific wave glow vocoder will be provided, trained with NVIDIA implementation, with default parameters.
Participants may fine tune the vocoder(s) with all the shared data. The vocoder weights will be shared, along with an inference script on Dec 15th, along with the baseline model.
You can find the complete set of rules here.
Challenge Dataset
Dataset description:
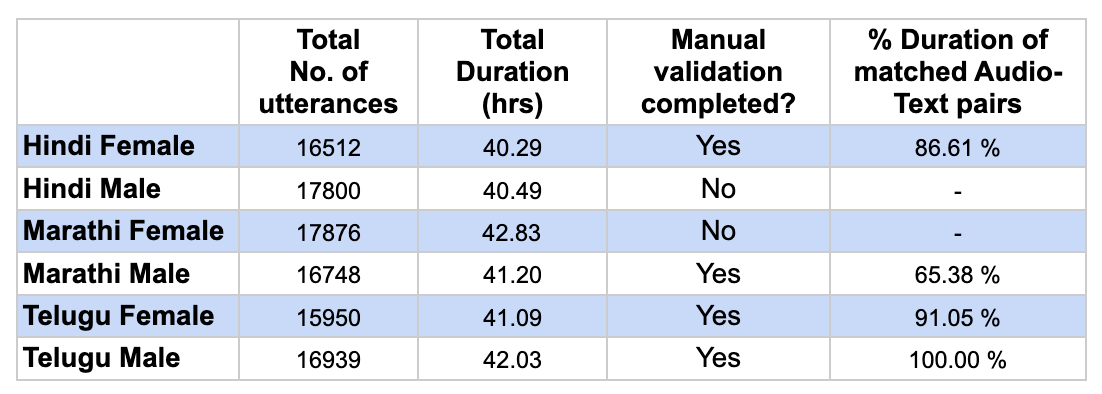
Languages: Hindi, Marathi, Telugu (1 male, 1 female voice artist from each language)
Studio quality recordings with 48kHz, 24 bits per sample
Sentences are mined from online sources as well as printed textbooks.
There are common sentences between male and female voice artists in a language.
Training data will have all special characters in the text, but only a few are allowed in the evaluation set. The expected characters in eval set are available at the challenge GitHub repository.

Challenge Evaluation
Submission from Participants
The challenge organizers describe a flask based inference API and how we can build one using this document. The API should accept 3 keys - text, spk, lang and respond with the wav file. We will not go into details on how we provisioned this system because that would be outside the scope of this blog. I hope to write a separate blog about it later.
Filtering Top-10 teams with objective metrics
Objective evaluation on all submissions is performed with a bag of automatic speech recognition (ASR) systems. The submissions are ranked based on Character Error Rate (CER) and consider the top 10 submissions for each subjective evaluation. The details regarding the ASRs to be used are shown below:
Hindi ASR
IndicWav2Vec wav2vec2 hi finetuned - https://huggingface.co/ai4bharat/indicwav2vec-hindi
Vakyansh wav2vec2 hi finetuned - https://huggingface.co/Harveenchadha/vakyansh-wav2vec2-hindi-him-4200
Telugu ASR
CSTD Telugu espnet joint attn-conformer - https://huggingface.co/viks66/CSTD_Telugu_ASR
IndicWav2Vec wav2vec2 te finetuned - https://huggingface.co/Harveenchadha/vakyansh-wav2vec2-telugu-tem-100
Marathi ASR
huggingface XLSR finetuned on openslr64 - https://huggingface.co/tanmaylaud/wav2vec2-large-xlsr-hindi-marathi
huggingface XLSR finetuned on openslr64 - https://huggingface.co/sumedh/wav2vec2-large-xlsr-marathi
Open-sourced ASR models (with <30% WER in their test sets) are used so that participants can utilize it to gauge their performance.
Subjective evaluation on Top-10 submissions
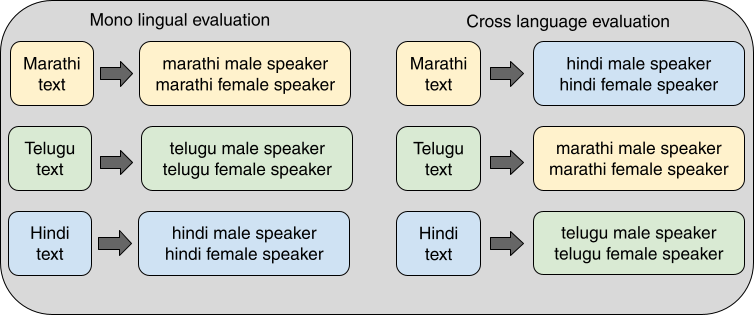
The selected TTS systems will be evaluated for 1) naturalness and 2) speaker similarity for all 6 voice artists in the 3 languages - Marathi, Hindi, and Telugu. For each language, there will be 10 native evaluators separately for checking the naturalness and speaker similarity leading to 20 evaluators for each track. Two types of evaluation are considered - mono-lingual and cross-lingual setups.

Evaluation setup:
The evaluation will be performed on a web portal.
In total, 144 total sentences (as shown in Tables 1 and 2) will be used for naturalness evaluation, for each submission.
The evaluators will be given a subset of 144 sentences without sentence repetition for each evaluator.
Test sentences are chosen from 4 categories - conversational, grammatically incorrect, out-of-domain (w.r.t. Training data), and in-domain (w.r.t. Training data). The 144 sentences will be balanced across these categories.
For each track, 48 synthesized sentences (24 mono and 24 cross) from each team will be mixed with 70 natural sentences, resulting in 550 sentences
Each evaluator has to validate 60 files (55 + 5 repeated)
Each sentence will be evaluated only once by a single evaluator at the end of the evaluation stage.
Naturalness evaluation with MOS: Here the quality of synthesized sentences is rated with respect to reference natural sentences. Evaluators were asked to rate both the synthesized and natural sentences (they were not told that natural sentences are also present).
The evaluators will be native speakers of the input text language. They will be remunerated for this task.
The evaluators will also listen to unseen natural sentences, randomly mixed with the synthesized audio.
A few files will be repeated for each evaluator to identify scoring consistency.
The average scores across all pairs will be reported for the leaderboard.
Furthermore, mono-lingual, as well as cross-lingual score averages, will be shown, along with the reference MOS.

Speaker similarity evaluation (will be carried out independent of Naturalness evaluation)
Speaker similarity will be evaluated for all 144 sentences corresponding to the defined text-audio pairs from the above Tables 1 and 2.
Along with the synthesized audio of the target speaker, a randomly selected reference from the target speaker will also be presented.
The evaluators for speaker similarity (different from those for naturalness evaluation) will be native of the language of the input text, and they will be instructed to ignore the content of the target speaker's utterance. They will be remunerated for this task.
Speaker similarity scores will be reported separately in the leaderboard, taking an average of all pairs.
Furthermore, mono-lingual, as well as cross-lingual score averages, will be shown.

Leaderboard
3 leaderboards are made public:
Main leaderboard: https://sites.google.com/view/syspinttschallenge2023/leaderboard/main-leaderboard?authuser=0
Detailed leaderboard: https://sites.google.com/view/syspinttschallenge2023/leaderboard/detailed-leaderboard?authuser=0
Evaluators summary: https://sites.google.com/view/syspinttschallenge2023/leaderboard/evaluator-summary?authuser=0
Mono and Cross-lingual sets for evaluation
Summary of our approach
We introduce VANI, a very lightweight multi-lingual accent controllable speech synthesis system. Our model builds upon disentanglement strategies proposed in RADMMM1 and supports explicit control of accent, language, speaker and fine-grained F0 and energy features for speech synthesis. We utilize the Indic languages dataset, released for LIMMITS 2023 as part of ICASSP Signal Processing Grand Challenge, to synthesize speech in 3 different languages. Our model supports transferring the language of a speaker while retaining their voice and the native accent of the target language. We utilize the large-parameter RADMMM model for Track 1 and lightweight VANI model for Track 2 and 3 of the competition.
There has been incredible progress in the quality of text-to-speech (TTS) models. However, most TTS models do not disentangle attributes of interest. Our goal is to create a multilingual TTS system that can synthesize speech in any target language (with the target language’s native accent) for any speaker seen by the model. The main challenge is disentanglement of attributes like speaker, accent and language such that the model can synthesize speech for any desired combination of these attributes without any bi-lingual data.
Our goal is to develop a model for multilingual synthesis in the languages of interest with the ability of cross-lingual synthesis for a speaker of interest. Our dataset consists of each speaker speaking only one language and hence there are correlations between text, language, accent and speaker within the dataset. Recent work on RADMMM tackles this problem by proposing several disentanglement approaches. We utilize RADMMM as the base model for track 1. For track 2, 3 we use the proposed lightweight VANI model. As in RADMMM, we use deterministic attribute predictors to predict fine-grained features given text, accent and speaker.
We leverage the text pre-processing, shared alphabet set and the accent-conditioned alignment learning mechanism proposed in RADMMM to our setup. This supports code switching by default. We consider language to be implicit in the phoneme sequence whereas the information captured by accent should explain the fine-grained differences between how phonemes are pronounced in different languages.
Data Pre-Processing
We utilize the Hindi, Telugu, and Marathi dataset released as part of LIMMITS challenge. We remove empty audio files and clips with duplicate transcripts. We parse files through the Automatic Speech Recognition model and generate transcripts. We select top 8000 data points per speaker with the least character error rate (CER) between ground truth and generated transcripts. This results in the dataset used for Track 2. For Track 1 and 3, we identify audio clips with maximal overlap in characters across speakers within a language 1 . We trim the leading and trailing silences and normalize audio volume.

Track 1: Large-parameter setup, Small-data
For track 1, our dataset is limited to 5 hours per speakers. Since our dataset is very limited, we apply formant scaling augmentation suggested in RADMMM with the goal of disentangling speaker S and accent A attributes. We apply constant formant scales of 0.875 and 1.1 to each speech sample to obtain 2 augmented samples and treat those samples belonging to 2 new speakers. This helps reduce correlation between speaker, text and accent by having the those variables same for multiple speakers and provides more training data. Our model synthesizes mels
using encoded text,
accent,
speaker,
fundamental frequency
and energy
as conditioning variables where F is the number of mel frames, T is the text length, and energy is per-frame mel energy average. Although we believe attribute predictors can be generative models, we use deterministic predictors where (F0^), (E^) and (Λ^) are predicted pitch, energy, and durations conditioned on text Φ, accent A and speaker S:
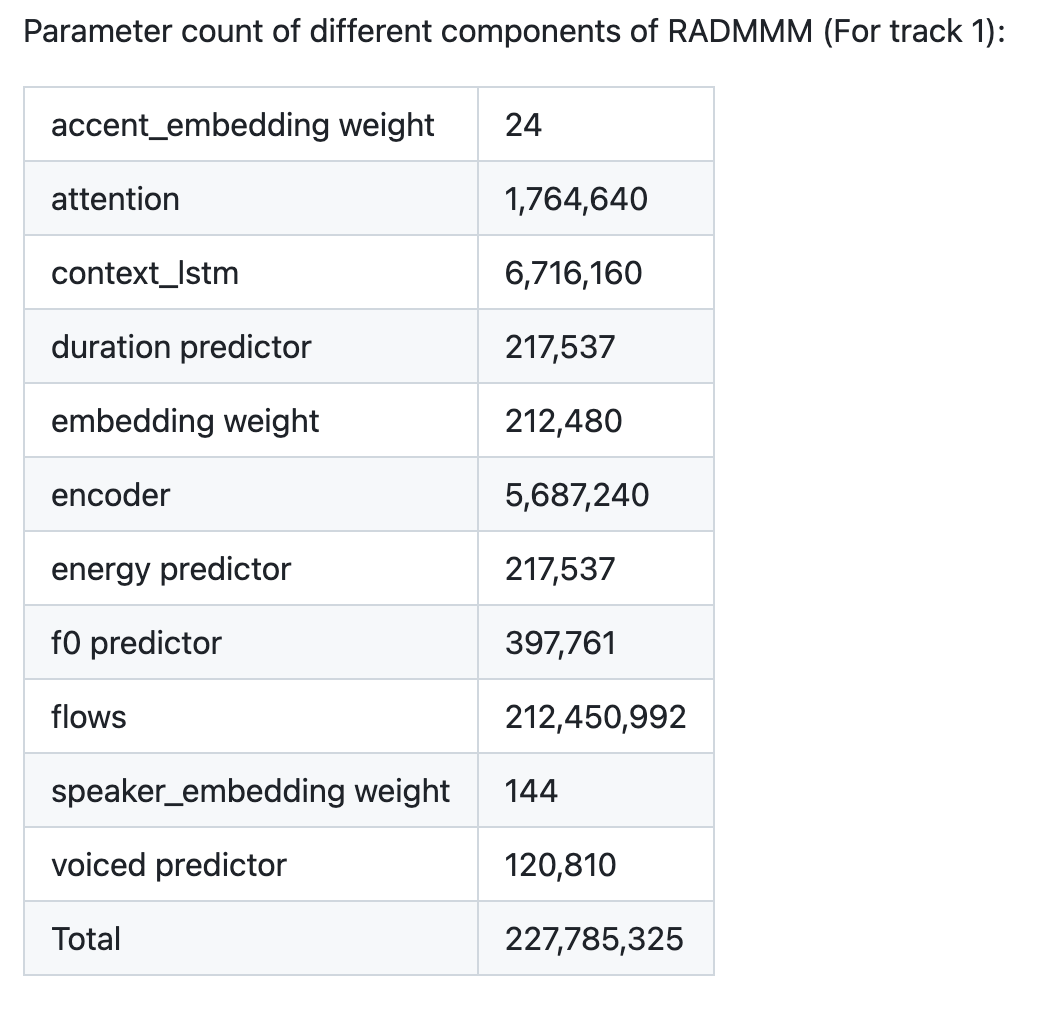

Track 2: Small-parameter, Large-data setup
Since our goal is to have a very lightweight model (< 5 million parameters), we replace RADMMM mel-decoder with an autoregressive architecture. Our architecture is very similar to Flowtron2 with 2 steps of flow (one forward and one backward). Each flow step uses 3 LSTM layers and is conditioned on text, accent, speaker, F0 and ξ.

Track 3: Small-parameter, Small-data setup
We utilize the model from Track 2 and the data and augmentation strategy from Track 1 as the model and data for Track 3.
Vocoder Setup
We use the HiFiGAN3 for Track 1 and Waveglow for Track 2 and 3 to convert mel-spectrograms to waveforms.
Results and Analysis
In this section, we evaluate the performance of the models in terms of content quality and speaker identity retention.
Character Error Rate (CER)
We calculate CER between the transcripts generated from synthesized speech and ground truth(GT) transcripts. Models with lower CER are better in terms of content quality.
Speaker Embedding Cosine Similarity
We use Titanet4 to get speaker embeddings and compare cosine similarity of synthesized sample against GT samples for the same speaker. Higher scores show better identity retention.
Evaluation Task Definition
Table 1 compares the Track1 model (RADMMM) against Track2 (VANI with nonparallel dataset - VANI-NP) and Track3 (VANI with limited parallel dataset - VANI-P) on mono-lingual resynthesis of speakers on 10 prompts in their own language (resynthesis task).

Table 2 compares the models in the three tracks where speech was synthesized in a speaker’s voice on 50 prompts outside of their own language (transfer task).

Analysis
We observe that even with the limited dataset, the large parameter RADMMM model outperforms the small parameter VANI model. We notice that Track 2 with a larger dataset retains identity and content quality better than Track 3 with limited data. However, all tracks do reasonably well on maintaining identity. We observe that on transfer, we’re able to achieve decent CER comparable to the resynthesis case, indicating our model preserves content on transferring language of the speaker. The identity retention in transfer task is worse than resynthesis as expected but doesn’t degrade much in VANI as compared to RADMMM demonstrating the importance of disentanglement strategies. We observe similar trend across tracks with human evaluation metrics (Table 3).

Conclusion
We utilize strategies proposed in RADMMM to disentangle speaker, accent and text for high-quality multilingual speech synthesis. We also present VANI, a lightweight multilingual autoregressive TTS model. We utilize several data preprocessing and augmentation strategies to preserve speaker identity in cross-lingual speech synthesis. Our model(s) can synthesize speech with proper native accent of any target language for any seen speaker without relying on bi-lingual data.
Results from challenge website below:
Track 1:

Track 2:
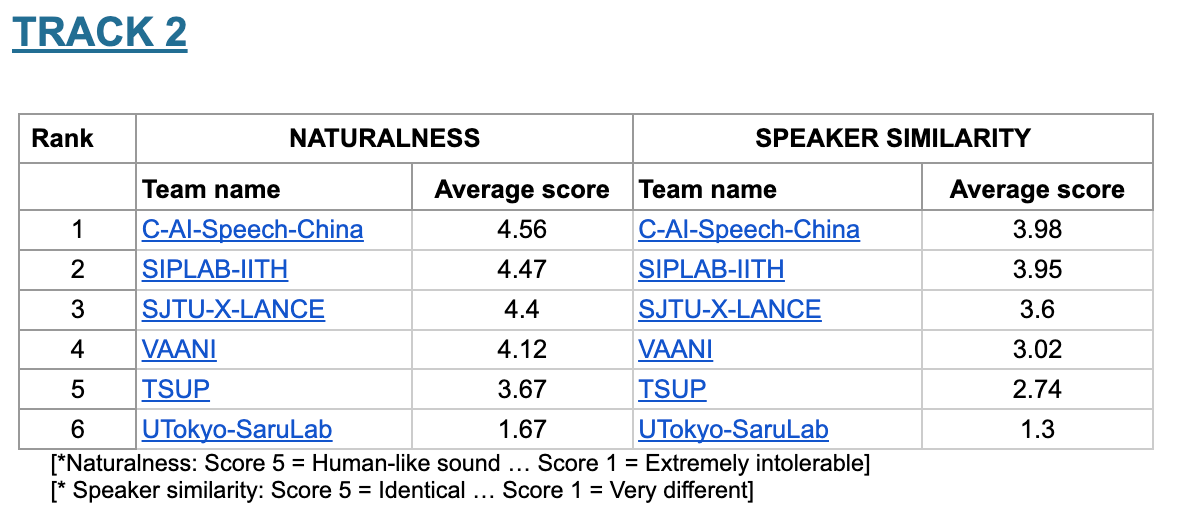
Track 3:

Background of SYSPIN
SYnthesizing SPeech in INdian languages (SYSPIN) is an initiative to develop large open-source text-to-speech (TTS) corpora and models for TTS systems in nine Indian languages in the area of agriculture and finance. Nine Indian languages considered for this project are Hindi, Bengali, Marathi, Telugu, Bhojpuri, Kannada, Magadhi, Chhattisgarhi, and Maithili.
A majority of the population in the country is still unable to use all the technological services due to language and literacy constraints. SYSPIN helps to reduce their barriers to voice-based technologies and creates a potential market for tech innovators and social entrepreneurs.
The output of this project will allow local innovation in emerging markets to develop products and services serving illiterate Indians and rural poor populations in their own medium of engagement with technology. The TTS corpus will be a unique resource for developing assistive technologies for people with speech and visual disabilities. The proposed 720 hours of open-source TTS data will open up opportunities for academic and industrial research.
More about SYSPIN: https://syspin.iisc.ac.in/
References
Project Page: https://aroraakshit.github.io/vani
Summary doc with dataset summary, model parameter summary and API usage: https://bit.ly/icassp_vani
Challenge website: https://sites.google.com/view/syspinttschallenge2023/spgc?authuser=0
Challenge overview paper: https://drive.google.com/file/d/1a_BjB_OaBqT5yQzG03tUbeWkkdcyxQzU/view
SYSPIN initiative: https://syspin.iisc.ac.in/
SPIRE Lab: https://ee.iisc.ac.in/~prasantg/index.html
RAD-MMM homepage: https://research.nvidia.com/labs/adlr/projects/radmmm/
NeMo implementation of HiFi-GAN: github.com/NVIDIA/NeMo
Waveglow checkpoints: github.com/bloodraven66/ICASSP_LIMMITS23
Rohan Badlani, Rafael Valle, Kevin J. Shih, João Felipe Santos, Siddharth Gururani, and Bryan Catanzaro, “Radmmm: Multilingual multiaccented multispeaker text to speech,” arXiv, 2023. Samples for RADMMM available here.
Rafael Valle, Kevin J Shih, Ryan Prenger, and Bryan Catanzaro, “Flowtron: an autoregressive flow-based generative network for text-to-speech synthesis,” in International Conference on Learning Representations, 2020. Samples available here.
Kong, J., Kim, J., and Bae, J. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, virtual, 2020. Code available here.